HL7 to FHIR
Outcome supports the direct import of HL7 v2, which we automatically convert to HL7 FHIR Bundles, including message traceability and provenance. We maintain a documented set of data mappings and transformations in spreadsheet format. At a high level, our HL7 to FHIR mappings cover the following segments > resources:

Healthcare Data Ingestion Pipeline
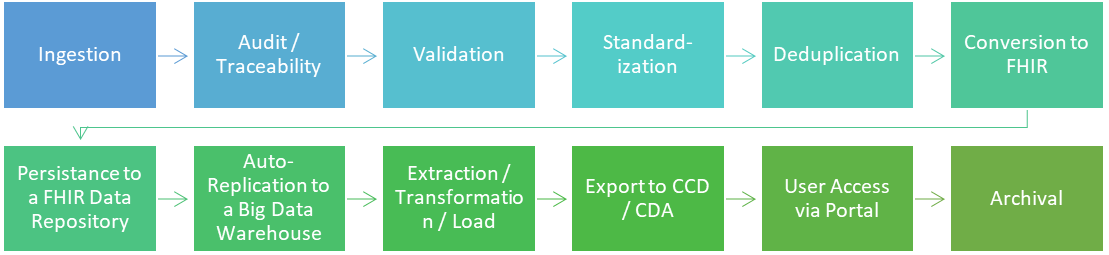
The platform supports both real-time and batch loading of data. The following workflow highlights key steps during the ingestion process:

Data Flow and Architecture:
- Data Intake: The system ingests incoming messages of various types (HL7V2, V3, FHIR, CCDA, etc.) through configurable adapters. These adapters handle variable timing and message formats. All received data is archived as it is received in a protected AWS S3 bucket in order to comply with regulatory requirements
- Parsing and Validation: The messages are parsed into a standardized HL7 FHIRv4 format for consistency. Data validation checks are performed to ensure data integrity.
- Transformation: Data is transformed based on pre-defined rules and mappings to conform to the data model. This may involve normalization, de-duplication, and enrichment.
- Data Storage: The final HL7v4 resource bundle is then stored in a scalable and secure FHIR v4 data repository. As data is ingested into the FHIR repository, it is also replicated to a data warehouse for near-real-time query and analytics.
- Aggregation and Output: Based on specific use cases, data can be aggregated at different levels and exported in various formats, including FHIR.
Among HL7 Event Types, we presently support:
- ADT – Admit, Discharge, Transfer
- ORU Laboratory
- ORU Radiology
- ORU Pathology
- ORU Transcriptions
- VXU Immunizations
- MDM Documents
- MRG – Merge
Healthcare Data Lifecycle
Outcome Healthcare ensures data quality is layered into all aspects of the implementation, to avoid a future state where the data is not adequate to meet the business needs. Learn more on Data Quality.